


AI in Supply Chain is Useless Without Clean Data
Modern supply chains generate millions of data points every day through shipment tracking, warehouse scans, GPS updates, APIs, invoices, and customer orders. Yet many logistics companies still struggle with slow decisions, false forecasts, and reactive operations.
The problem is not the lack of supply chain data. Most organizations already have enough operational information in their transportation, warehousing, procurement, and inventory systems.
The real issue is fragmented ETL pipelines and poor data infrastructure. Disconnected systems, late API synchronization, duplicate records, and inconsistent data quality prevent businesses from turning raw data into actionable intelligence.
That's why supply chain companies that invest only in AI for logistics do not see the expected results. Without clean, connected, and automated data pipelines, even advanced supply chain technology cannot support fast and reliable decision-making.
In this blog, you will learn how dirty data pipelines affect supply chain decisions and how businesses can build AI-ready logistics operations.

What Is an ETL Pipeline in Supply Chain Management?
An ETL pipeline is the system responsible for collecting, cleaning, organizing, and moving supply chain data from multiple platforms into one usable structure for analytics and operational decision-making.
ETL stands for: Extract, Transform, and Load
In logistics and supply chain management, data usually comes from several disconnected systems, such as:
- Transportation Management Systems (TMS)
- Warehouse Management Systems (WMS)
- ERP platforms
- Carrier APIs
- Freight visibility tools
- Inventory systems
- Supplier portals
- IoT tracking devices
- EDI transactions
- Customer order platforms
The ETL process extracts data from these systems, transforms it into a standardized format, and loads it into dashboards, cloud data warehouses, or analytics platforms.
On paper, the process sounds efficient and straightforward.
But in reality, most supply chain data pipelines are fragmented, delayed, inconsistent, and full of data quality issues. That is where operational intelligence starts breaking down.
Looking for Custom AI Solutions ?
The 2 Biggest Problems Caused by Dirty Data Pipelines in Logistics
1. Fragmented Data Across Multiple Systems
Different departments often work on separate platforms that do not synchronize properly with each other. Procurement teams use one system. Transportation teams rely on another. Warehousing operates independently. Carrier updates may arrive through APIs, EDI feeds, spreadsheets, and emails at the same time.
As a result, companies struggle to create a unified operational view.
Inventory systems may refresh every few hours, while shipment tracking updates every few minutes. Supplier data may sync once daily, while customer portals expect real-time information.
This creates conflicting operational insights across teams.
When executives look at dashboards, they often see incomplete or outdated supply chain data. That makes real-time logistics decision-making extremely difficult.
2. Poor Data Quality Creates Unreliable Analytics
Supply chain analytics platforms are only as reliable as the data feeding them. Unfortunately, logistics data quality issues are extremely common. Most organizations regularly deal with:
- Duplicate shipment records
- Missing ETA updates
- Incorrect SKU mapping
- Delayed API synchronization
- Inconsistent carrier naming conventions
- Manual spreadsheet errors
- Incomplete delivery statuses
These problems may look small individually, but together they create major operational blind spots.
A dashboard may look visually advanced, but if the underlying data is inaccurate, every operational insight becomes questionable.
That lack of trust spreads quickly across logistics operations. Teams begin manually validating reports before taking action. Meetings become focused on identifying which numbers are correct instead of solving actual supply chain disruptions.
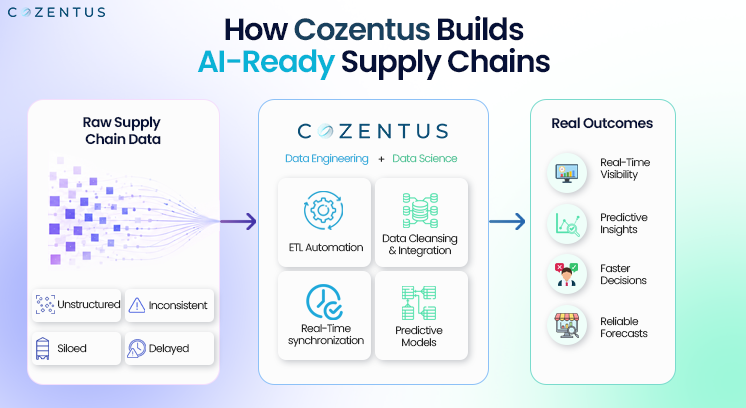
How to Build AI-Ready Supply Chain Data Pipelines
To turn supply chain data into real operational intelligence, companies need more than dashboards and AI tools. They need a clean, connected, and automated data infrastructure.
Modern logistics organizations are now focusing on building ETL pipelines that can process operational data accurately and in real time.
Here are the key steps businesses should focus on:
1. Remove Data Silos
Transportation, warehousing, procurement, and inventory systems should be connected through centralized data pipelines. Unified data visibility helps teams make faster and more accurate decisions.
2. Automate Data Validation
Modern ETL systems should automatically identify duplicate records, missing fields, delayed API responses, and inconsistent formats before the data reaches analytics dashboards. In fact, Cozentus has already built a similar platform using Intelligent Document Processing (IDP).
3. Enable Real-Time Data Synchronization
Supply chain disruptions happen quickly. Businesses now can no longer depend on late updates or overnight batch processing. Real-time synchronization improves visibility and response speed.
4. Standardize Data Across Systems
Carrier names, shipment milestones, inventory statuses, and operational events should follow standardized formats across all platforms. This improves reporting accuracy and AI performance.
5. Build AI-Ready Data Infrastructure
AI in logistics only works when the underlying data is structured, clean, and reliable. Businesses investing in predictive analytics and automation must prioritize scalable ETL architecture first.
Conclusion: Your Supply Chain Is Only as Smart as Your Data
The real challenge for supply chain companies is turning the raw data they generate every day into reliable, real-time intelligence that supports fast operational decisions.
That only becomes possible when ETL pipelines are clean, connected, automated, and scalable.
No dashboard, analytics platform, or AI engine can consistently outperform poor data quality.
Dirty pipelines create slow decisions. Slow decisions create expensive supply chains.
The companies building strong supply chain data infrastructure today will become the organizations capable of making faster, smarter, and more profitable logistics decisions tomorrow.


