


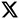
Why Every Supply Chain Failure Starts with Bad Data and How to Fix It
If you search for supply chain failures, you will find stories about port congestion, labour shortages, rising freight costs, and missed deliveries.
But in most cases, the real problem started much earlier, with “bad data”.
Wrong shipment updates. Incomplete inventory records. Delayed cost information. Data that looked good enough on a dashboard but did not reflect what was actually happening on the ground.
Across logistics, manufacturing, and distribution, poor data quality quietly drives poor decisions. Teams plan with the wrong numbers. Risks go unnoticed.
This is not a technology problem, as most organizations already have advanced systems and analytics in place. The issue is that those systems depend on data that is fragmented, outdated, or manually handled.
This blog explains why poor data quality is the root cause of most supply chain failures, how it quietly damages performance, and what leaders must do now to fix it before it raises the stakes even higher.

Why Data Quality Is the Foundation of Every Supply Chain
Modern supply chains run on decisions. Every day, teams decide:
- How much to produce
- Where to ship
- Which route to use
- How to price and allocate inventory
- How to respond to risks and disruptions
Every one of those decisions depends on data.
When supply chain data is accurate, decisions are made with confidence and fast. When data is unreliable, teams hesitate, double-check, and go back to manual work.
That hesitation is where delays, cost overruns, and service failures begin. Bad data does not cause one big mistake. It causes thousands of small ones that compound over time.
The Most Common Supply Chain Data Problems
High-performing blogs consistently highlight the same root issues. These are not theoretical problems. They show up daily in real operations.
1. Data Lives in Silos
ERP systems, TMS platforms, WMS tools, carrier portals, spreadsheets, emails, and PDFs all hold pieces of the truth. No single system reflects reality end-to-end. Teams spend more time reconciling data than acting on it.
2. Data Arrives Too Late
Weekly or monthly reports explain what has already gone wrong. They do not help prevent the next issue. Late data leads to reactive supply chain management.
3. Inconsistent Definitions
Different teams define on-time delivery, cost, or inventory availability differently. This creates internal conflict and poor decision-making.
4. Heavy Reliance on Manual Processes
Freight invoices, shipping documents, and compliance records are still handled manually in many organizations. Manual entry introduces errors and delays.
5. Low Trust in Data
When teams export data into spreadsheets to validate it, trust in the system is already lost. This is one of the strongest indicators of poor supply chain data quality.
Supply Chain Technology Alone Does Not Solve the Problem
Many companies try to fix supply chain data problems by buying new technology. Control towers, visibility platforms, AI dashboards, and analytics tools are common choices. These tools are important, but they do not solve the core issue on their own.
Technology does not correct poor data quality. It makes the problem more visible. When supply chain data is incomplete or inaccurate, analytics produce misleading insights. AI models learn incorrect patterns. Alerts become unreliable and are often ignored.
Over time, teams lose confidence in dashboards and reports. They return to spreadsheets, emails, and manual checks to validate information. Decision-making slows down, and risks are missed. The real problem is not the technology itself. The real problem is the quality of the data that powers it.
The Real Cost of Poor Data Quality in Supply Chain Business
Poor supply chain data quality has direct and indirect costs.
Direct costs include:
- Missed SLAs and penalties
- Higher freight and inventory costs
- Invoice errors and revenue leakage
- Expedited shipments to recover failures
Indirect costs are often larger:
- Extra headcount to reconcile data
- Slower decision-making
- Poor customer experience
- Delayed sustainability and compliance reporting
By 2026, these costs will increase.
Customers will expect real-time visibility. Regulators will demand defensible data. Sustainability metrics will be scrutinized. Organizations that cannot trust their data will struggle to compete.
What Good Supply Chain Data Actually Looks Like
Good data is not perfect data. Good data is something that is usable.
It is:
- Timely enough to act on
- Consistent across teams
- Connected across systems
- Trusted by operations
In logistics, good data means knowing:
- Where a shipment is now
- What risk it carries
- What it will cost
- What action should be taken next
This is the difference between reacting to problems and managing them proactively.
5 Steps to Fix Supply Chain Data Problems Easily
Leading supply chain organizations follow a practical and repeatable approach for their data. This is not a one-time clean-up. It is a capability.
Step 1: Connect All Supply Chain Data in One Place
Do not replace every system in your supply chain. Connect them instead. Unify ERP, TMS, WMS, partner feeds, and documents into one operational view so all teams work with the same data and make aligned, faster decisions.
Step 2: Use Clear and Common Data Definitions
Clearly define the data that matters most, such as delivery status, inventory availability, and cost components. Publish simple definitions and apply them consistently across systems, regions, and teams to avoid confusion and conflicting decisions.
Step 3: Capture Data Automatically at the Source
Reduce manual data entry wherever possible. Use intelligent document processing to capture information from freight invoices, bills of lading, and shipping documents accurately, improving data quality before errors enter your supply chain systems.
Step 4: Track and Fix Data Quality Issues Continuously
Track data quality issues such as missing fields, inconsistent values, and late updates. Assign clear ownership to fix root causes rather than repeatedly correcting errors, ensuring data remains reliable over time.
Step 5: Act on Real-Time Data Instead of Reports
Static reports only explain what happened in the past. Use real-time alerts and predictive analytics to identify risks early, prioritize actions, and guide teams toward faster, more informed supply chain decisions.
How AI & Predictive Analytics Reduces Supply Chain Risks
AI and predictive analytics add real value to supply chain management only when the data foundation is strong. Clean, accurate, and trusted data allows teams to move from reacting to problems to preventing them.
With high-quality supply chain data, AI can support critical decisions such as:
- Predicting shipment delays before customers are impacted
- Detecting freight invoice errors and unusual cost patterns
- Scoring risks to help teams focus on the most critical exceptions
- Running scenarios to balance cost, service, and sustainability goals
When data quality is poor, AI produces unreliable outputs. Predictions become inconsistent, alerts trigger too often or not at all, and dashboards lose credibility. Teams then return to manual checks and spreadsheets, slowing down operations.
The purpose of AI in supply chains is not to create more reports or predictions. The real goal is to enable faster, clearer, and more confident decisions based on data that reflects what is actually happening across the supply chain.
2026 Will Be a Different Reality for Supply Chain Leaders
Supply chains are changing faster than ever before. They are becoming more connected, more data-driven, and more visible across regions, partners, and customers. What worked even two or three years ago will not be enough going forward.
By 2026, expectations across the supply chain will fundamentally change.
- Real-time supply chain visibility will no longer be optional. Customers and internal teams will expect accurate status updates at any moment, not after the fact.
- Sustainability and emissions data will face closer scrutiny. Companies will need reliable, auditable data to support regulatory and customer reporting.
- Customers will demand proactive communication. They will expect to be informed about risks and delays before problems occur.
- Manual processes will not scale. Spreadsheets, emails, and manual checks will slow operations and increase errors as volume and complexity grow.
Organizations that invest now in strong data foundations will move with confidence. They will predict risks earlier, respond faster, and make better decisions. Those that delay will spend more time explaining failures, managing escalations, and reacting to issues that could have been prevented.
Final Thought: Fix the Data, Fix the Supply Chain
Most supply chain failures do not happen because of one unexpected event. They happen because decisions are made using incomplete or unreliable data. Delays, cost overruns, and service issues are often the result of poor information, not poor execution.
New trucks, more dashboards, or larger platforms will not solve this problem on their own. What truly will change the outcomes is clean, connected, and trusted data that helps leaders make better decisions every day.
Organizations that treat data as a strategic asset will move faster, manage risk better, and stay competitive as expectations rise. Those who delay will spend more time reacting than leading. Now is the time to fix the data before it makes the gap impossible to ignore.
Talk with our experts about fixing your data in 2026.


