

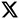
Why the Gap Between AI POC and Production Is So Big
Most companies experimenting with AI in logistics and supply chain think they are much closer to production than they actually are.
They build a model, see predictions working, and maybe even put together a dashboard that looks really convincing. At that point, it feels like the hardest part is already done.
But that assumption is usually where things begin to go wrong.
A working AI prototype does not mean you have a production-ready AI system. The gap between the two is not just technical - it’s operational, architectural, and, honestly, often underestimated.
In most cases, the issue is not the model at all. It is everything around it. More specifically, the problem sits in your ETL processes and data pipeline architecture. That is where things quietly start breaking without being obvious at first.
In this blog, you’ll understand where that gap actually comes from, why most AI systems fail to scale in logistics, and what to fix in your data pipelines before moving to production.

Why Most AI POCs in Logistics Fail in Production
A lot of AI proof-of-concept (POC) projects in logistics look successful in the beginning. They show results, they generate insights, and they get internal buy-in pretty quickly.
But things change once they move into production.
The main reason is simple. POCs are built in controlled environments, while real logistics systems are far from this.
Here is what that difference actually looks like in practice:
- Clean, structured data in POCs vs messy, inconsistent data in production
- Limited integrations vs multiple interconnected systems
- Static datasets vs continuous, real-time data streams
- Minimal disruptions vs constant exceptions and operational edge cases
In a POC, everything behaves as expected. In production, almost nothing does.
Because of this mismatch, even well-built AI models in the supply chain start producing unreliable outputs. The model is doing its job, but the data it receives is no longer stable or consistent.
What is ETL in Logistics? The Foundation of Scalable AI Systems
If you want to build scalable AI in logistics, you need to understand ETL properly. Not only is it a backend process, but it is also the foundation of everything your AI depends on.
At a basic level, ETL includes three steps:
- Extract – Pulling data from TMS, WMS, GPS, APIs, EDI systems, and sometimes even emails
- Transform – Cleaning, standardizing, and correcting inconsistencies in the data
- Load – Feeding that processed data into AI models and analytics platforms
This sounds pretty straightforward, but logistics data is not always clean or predictable.
In real-world scenarios, you deal with:
- Carrier data arriving in completely different formats
- GPS signals dropping or lagging without warning
- EDI messages that are delayed or incomplete
- Manual data entries that introduce inconsistencies
Sometimes, the same shipment can show different statuses across systems, and your pipeline has to decide which one to trust.
So in reality, your pipeline is moving data and is constantly trying to make sense of it.
That is why data pipeline management in logistics is much more complex than it appears from the outside.
Common Data Pipeline Challenges in AI Logistics Projects
Most AI POCs in logistics and supply chain are built quickly to prove value. That usually means teams simplify or skip parts of the data pipeline.
Those shortcuts work in the short term, but they become problems later.
Some of the most common challenges include:
- Lack of real-time data integration, with heavy reliance on batch processing
- Hardcoded transformation logic that breaks when data formats change
- No structured handling of missing, delayed, or incorrect data
- No monitoring, alerting, or visibility into pipeline failures
Initially, everything still appears to work. But as the system scales, these issues start showing up in different ways.
You start to see:
- Predictions becoming inconsistent
- Insights arriving too late to be useful
- Conflicting data across systems
- Less trust from operations teams
At this stage, the AI model is often blamed. But in most cases, the actual issue lies in the data pipeline, not the model.
AI POC to Production Checklist: ETL and Data Pipeline Audit Framework
If you are serious about moving from an AI POC to a production-ready system, you need to evaluate your data pipeline in detail. Below is a practical checklist that helps identify gaps in ETL and data pipeline architecture for logistics AI systems.
1. Data Source Reliability in Logistics Systems
The first question is simple but important. Can your system rely on the data it receives?
To answer that, you need to look at:
- The number of systems integrated into your pipeline
- Stability and uptime of APIs and external data feeds
- Availability of fallback mechanisms when data is missing
- Frequency and patterns of data failures
In logistics, data interruptions are normal. If your system is not designed to handle them, it will fail under real conditions.
2. Real-Time Data Processing and Pipeline Latency
In real-time logistics operations, timing plays a critical role. Even small delays can reduce the effectiveness of your AI system.
You need to evaluate the following things:
- End-to-end data pipeline latency
- Whether the system uses batch or streaming architecture
- Frequency of data refresh and updates
A delay of even 15 - 20 minutes can impact predictions, alerts, and decision-making. It may not seem like much, but in operations, it matters.
3. Data Transformation and Standardization in Supply Chain
Raw logistics data cannot be used directly. It needs to be processed and standardized before it becomes useful.
You should evaluate:
- Whether the transformation logic is consistent across systems
- How edge cases and anomalies are handled
- Whether data processing workflows are reusable or ad hoc
If the transformation is not handled properly, the entire pipeline becomes unreliable, even if everything else is working fine.
4. Data Quality Management for AI in Logistics
Data quality is one of the most critical factors for AI model performance in logistics.
Key checks include:
- Validation rules for incoming data
- Schema enforcement across systems
- Handling of missing or incomplete data
- Detection of anomalies and inconsistencies
Bad data does not just affect accuracy. It affects trust. And once trust is lost, adoption becomes difficult.
5. Error Handling and Fault Tolerance in Data Pipelines
Failures are a normal part of production systems. What matters is how your system responds to them.
Important capabilities include:
- Retry mechanisms for failed data ingestion or processing
- Logging and debugging tools for tracing issues
- Alert systems that notify teams of failures
If your pipeline fails silently, the impact is usually discovered too late.
6. Scalable Data Pipeline Architecture for Logistics AI
As your operations grow, your system needs to handle increasing data volume and complexity.
You should assess:
- Whether the pipeline can scale with data growth
- Use of distributed processing where required
- Cloud-based infrastructure and flexibility
Systems that are not designed for scale tend to break under pressure, often unexpectedly.
7. Data Lineage and Traceability in AI Systems
When something goes wrong, you need to understand why. That is where data lineage becomes important.
Key considerations include:
- Tracking the origin of data
- Monitoring how data is transformed
- Understanding what inputs are used by the model
This helps with debugging, compliance, and overall system transparency.
8. Integration of AI with TMS, ERP, and Logistics Platforms
AI systems do not operate in isolation. They need to integrate with the existing logistics infrastructure.
You should evaluate:
- API readiness and flexibility
- Data exchange standards across systems
- Level of automation in integrations
Manual processes might work temporarily, but they do not scale.
9. Data Security and Compliance in Logistics AI Platforms
Logistics data often includes sensitive business and customer information. Protecting it is critical.
Important areas include:
- Data encryption practices
- Access control mechanisms
- Compliance with relevant regulations
Security is often overlooked during POCs, but it becomes essential in production environments.
10. Monitoring and Observability for Data Pipelines
You cannot manage what you cannot see. Monitoring is essential for maintaining system reliability.
Key components include:
- Real-time alerts for failures and anomalies
- Performance dashboards for tracking pipeline health
- Mechanisms to detect and resolve issues quickly
Without observability, problems remain hidden until they impact operations.
What a Production-Ready AI Logistics Platform Looks Like
A production-ready AI-powered logistics platform is not only about models and dashboards. It includes a complete system that is built for reliability and scalability.
Typically, such a system includes:
- Real-time, event-driven data pipelines
- Hybrid architectures combining batch and streaming
- Strong data validation and quality frameworks
- Automated error handling and recovery mechanisms
- Scalable cloud infrastructure
- End-to-end monitoring and observability
These elements work together to ensure that the AI system delivers consistent and reliable outcomes.
Conclusion: Fix Your Data Pipelines First
Building a successful AI system in logistics takes more than just a working model. It really comes down to having a strong, reliable foundation that can handle real-world messiness. Not just clean, controlled environments, like in the prototype. Well-designed ETL processes help structure that data, scalable data pipelines manage continuous flow and volume, and a stable architecture ensures the system performs reliably over time.
The shift from AI POC to production in logistics is not a small step. It actually changes how systems are designed, connected, and maintained over time. When outputs start feeling off or inconsistent, the issue is mostly how data is flowing through the system, somewhere in the pipeline.
At Cozentus, a lot of the focus goes into strengthening this layer so AI systems can perform consistently in live environments. We help you:
- Design scalable, real-time data pipelines for logistics data
- Improve data quality through validation and standardization
- Make smooth integration across TMS, WMS, and other systems
This is where AI starts becoming stable, usable, and genuinely valuable.



