


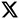
The Problem with Traditional ETA Predictions
In many operations, ETA has long been treated as a dependable number. A shipment leaves a facility, the system calculates the route, and an estimated arrival time appears on the screen. The number appears reliable, and teams assume the delivery will reach exactly as planned.
The challenge is that real-world operations don’t usually follow a predictable path. Traffic conditions change, ports experience congestion, weather disrupts schedules, and supplier delays can quickly alter the expected timeline. As these factors evolve, the ETA that once looked precise often becomes less reliable.
Traditional ETA systems were designed using relatively simple logic. Most rely on route distance, historical transit averages, and scheduled departure times to generate a single prediction. This creates a single prediction that assumes conditions will remain consistent, which is not usually the case.
Modern logistics networks are far more complex. Numerous variables influence movement every hour, making static predictions increasingly difficult to trust. This is why many supply chain companies are shifting toward machine learning driven risk prediction models that evaluate delay risk more intelligently.

What Static ETA Systems Actually Do
Traditional ETA engines operate using rule-based calculations. They use fixed formulas based on historical travel times and route distances. The logic is straightforward.
If a truck usually takes six hours to travel a route, the system predicts the next trip will take six hours as well. The ETA becomes a single timestamp. While this approach worked reasonably well when networks were simpler, it struggles in modern supply chain operations.
Static ETA models typically fail in three areas:
- Limited Variables: Traditional systems often rely on only a few inputs, such as route distance, average travel time, and scheduled departure.
- No Real-Time Learning: These systems do not continuously learn from new data. They depend heavily on static historical averages.
- No Uncertainty Modeling: The biggest limitation is that static ETAs assume everything will go exactly as planned. They provide a single arrival time instead of showing the range of possible outcomes.
Why ETA Prediction Is a Complex Problem
Predicting arrival time seems simple on the surface. In practice, it is one of the most complex forecasting problems in operations. Consider what actually influences a delivery.
A single shipment may be affected by dozens of variables, including:
- Traffic congestion
- Weather changes
- Port or terminal delays
- Carrier capacity fluctuations
- Customs inspections
- Driver behavior
- Equipment breakdowns
- Network congestion
Machine learning models are designed to identify patterns across large and complex datasets. They analyze thousands of historical events and real-time signals to detect correlations that humans or simple formulas would miss.
This ability to process large volumes of data is the reason ML systems are dramatically improving prediction accuracy across multiple industries.
In logistics, especially, modern predictive systems can achieve ETA accuracy above 90% even a day before delivery.
But the most important shift is not just accuracy. It is the ability to measure uncertainty.

How Machine Learning Builds Probabilistic Predictions
Probabilistic ETA means predicting the likelihood of different arrival times by showing the probability of various outcomes. Probabilistic models evaluate uncertainty by calculating the likelihood of events based on historical patterns and real-time signals.
Machine learning models generate probabilistic ETA insights through several steps.
1. Data Collection and Integration
The process begins with gathering large volumes of operational data.
Typical inputs include:
- GPS and telematics feeds
- traffic conditions
- weather patterns
- carrier performance history
- shipment milestones
- port and terminal congestion
- route characteristics
These datasets create a detailed picture of how operations behave. Many advanced platforms integrate data directly from enterprise systems such as transportation management platforms, warehouse systems, and ERP environments.
2. Feature Engineering
Feature engineering transforms raw data into signals that the model can interpret.
Examples include:
- average delay on specific routes
- seasonal congestion patterns
- carrier reliability scores
- historical dwell time at facilities
Feature engineering is often the most important step in building high accuracy models.
3. Model Training
Machine learning models such as Random Forest, Gradient Boosting, and Neural Networks analyze patterns across millions of historical events.
Hybrid models are often used because they capture both linear and non-linear relationships in the data. The goal is to learn how variables interact to influence arrival time.
4. Probabilistic Forecast Generation
Instead of predicting a single number, the model generates a probability distribution. This distribution reflects the range of potential arrival times and the likelihood of each outcome.
The result is a probabilistic ETA that shows possible outcomes instead of a single fixed prediction.
Introducing Probabilistic Risk Scoring
Once arrival probabilities are calculated, the system can convert them into operational risk scores. Risk scoring is where machine learning becomes operational intelligence, helping teams predict risks before they occur.
For example, a shipment may receive a risk score based on factors such as:
- likelihood of delay
- financial impact of disruption
- customer service commitments
- downstream network dependencies
Each shipment, order, or movement receives a dynamic score. These scores help teams prioritize where intervention matters most. Advanced systems continuously update risk scores as new signals appear.
If weather conditions change or a carrier misses a milestone, the risk score automatically adjusts. Executives gain visibility into the network before disruptions escalate.
Why Risk Scoring Is More Valuable Than Static ETAs
Executives rarely care about the exact minute something arrives. What they care about is risk.
A static ETA may say 4:00 PM, but it does not answer the question that matters most. “How likely is it to be late?”
Probabilistic risk scoring answers this question clearly and helps teams improve operations in several ways.
- Better Prioritization: Teams can focus on shipments with the highest probability of disruption.
- Earlier Intervention: If risk begins to rise hours or days in advance, corrective action becomes possible.
- Clearer Decision Making: Instead of reacting to surprises, teams make proactive adjustments.
The Supply Chain Use Case
Supply chains offer one of the clearest examples of this transformation.
Traditional logistics tracking often shows a simple milestone progression. Shipment departed. Shipment in transit. Shipment arriving.
However, this visibility doesn’t tell the full story.
Modern supply chains generate massive amounts of data from orders, carriers, facilities, and sensors. Machine learning systems analyze these signals in real time to detect emerging disruptions and score their potential impact.
For example, if a shipment leaving a port historically experiences congestion delays on certain days of the week, the model can detect the pattern and increase risk scores early.
This early warning allows teams to:
- Reroute shipments
- Adjust inventory allocations
- Inform customers proactively
Some advanced platforms are beginning to integrate probabilistic risk models directly into supply chain control towers.
The result is a shift from tracking shipments to predicting outcomes. Organizations that adopt this approach gain significantly better resilience and service reliability.
Conclusion: Predictive Intelligence offers Better Risk Management
Over the next decade, probabilistic forecasting is expected to become a standard capability across operational platforms. Several key trends are driving this shift.
First, data availability continues to grow. Sensors, connected devices, and digital platforms generate a constant stream of operational signals across networks.
Second, machine learning models are becoming more advanced, efficient, and easier to deploy at scale.
Traditional ETA systems were built for a simpler world. Today’s operations are complex and constantly changing, making a single predicted timestamp unreliable.
Machine learning introduces a smarter approach by modeling probability and uncertainty. With probabilistic risk scoring, organizations can identify disruptions earlier, anticipate risk, and make confident decisions before problems escalate.



